Discovery: Crawl Infrastructure & A/B Testing Exposure
About this document
This is an investigative discovery piece. We have collated as much data as we can observe from the front end - HTTP response headers, cookies, cache state, redirect chains, comparable peer sites, and Google Search Console signals. Everything in this document is grounded in evidence we can see and reproduce externally.
We should be upfront about where we are coming from: we are not developers and we are not IT infrastructure specialists. We work within the marketing and product space, and our perspective is an SEO and crawl-behaviour one. We have tried our best, where possible, to provide as much technical insight as we could collect on our own, but accurate diagnosis and the design of any fix require further input and expertise from the existing engineering team. Code-level recommendations in this document are intended as a starting point for that conversation, not as a prescription.
There is a layer of this we cannot see from outside. We have no visibility into the backend code, the Vercel project configuration, the middleware stack, the commercetools setup, the legacy Cloud9Living integration, or the historical reasons certain decisions were made. Our evidence base is HTTP responses across multiple vantage points, comparisons with other commercial sites, comparisons with other Vercel-hosted clients we have run the same diagnostics against, and the limited inside view we do have within Cloudflare and Vercel themselves. We have sanity-checked findings wherever we could, but the further we move from the response headers and into the architecture behind them, the more likely it is that we are inferring something the inside view would describe differently. Some of what looks like a misconfiguration may turn out to have a deliberate rationale we are not aware of, and some recommendations may need to be adjusted once we understand the constraints the team is working within. Where that is the case, we would rather be told than guess.
A second caveat: when we run our external checks against the site (curl from different vantage points, GSC URL Inspection, peer comparisons), we get inconsistent responses. The same URL can return different headers, different cache states, and occasionally different status codes between two requests minutes apart. We are not yet sure whether this is the result of bot protection or WAF rules, miscommunication between Cloudflare, Vercel and the legacy backend, request-routing variance at the edge, or whether what we see is genuinely what Googlebot also sees. Our evidence is point-in-time, and some of what we describe may need to be reconfirmed by engineering against logs we cannot see. We have tried to call this out wherever it bears on a specific finding.
We would like to treat this as the start of a conversation rather than a finished verdict. Our goal is to work alongside the development team and other stakeholders, share what we have found, hear the context behind the current setup, and arrive at a solution together. Where this document is wrong or incomplete, we want to know.
On testing within SEO
Unlike almost every other channel, including paid search, UX, UI, and even testing in development environments, brands have been notoriously reluctant when it comes to SEO testing. Hypotheses go unchecked, changes are debated rather than measured, and the bar of "prove it first" is set far higher for SEO than for any neighbouring discipline. As a group we should give ourselves permission to test theories even when we don't have all the answers up front. That is how every other channel learns, and SEO should be no different.
This document falls squarely into that mindset. We are flagging things now because something isn't quite right, and the signals we can see from outside are enough to justify acting rather than waiting. We do not have the full picture from one side alone, so we need to work with the internal teams to combine what they can see in the stack with what we can see from the crawl, and to test our theories together. The findings here are propositions to validate, not verdicts to defend.
Executive summary (non-technical)
This audit puts forward three working hypotheses about how Google currently experiences the site. Each is grounded in evidence we can observe externally and reproduce, and each is offered to the engineering and platform teams to validate, challenge, or refine. Where the internal picture changes the conclusion, we want to know.
Hypothesis 1: robots.txt is being served through the legacy stack, and that is degrading crawl performance
What we think. The robots.txt file is the first request Google makes before crawling anything else, and it needs to be fast, reliable, and consistent. The content of ours is correct; the list of allowed and disallowed paths is right. Our hypothesis is that the delivery path is wrong: every request for /robots.txt appears to be routed past the Vercel edge and forwarded to the legacy Cloud9Living backend, which generates the response on the fly, attaches three cookies to it, and instructs caches not to store the result.
Why we think it. Three independent signals point the same way:
- Latency. Google records an average response time of ~440ms for our robots.txt, against a benchmark of ~50ms for a properly edge-served equivalent. Multiplied across 212 daily fetches, this represents crawl budget that could otherwise be directed at product pages.
- Reliability. On 11 April, Google fetched our robots.txt 9 times in roughly two hours; 4 of those came back as "Not Fetched – N/A". When Google cannot retrieve robots.txt, it backs off from crawling the site as a whole until it can.
- Caching behaviour. The response carries cookies (one of them named
frontend_cloud9living, which is the strongest indicator that the legacy backend is in the path), and Vercel cannot cache a response carrying cookies. Every fetch becomes an origin fetch, even though the file barely changes.
If validated, the resolution is straightforward. Move the robots.txt content into the Vercel platform itself, so the file serves from the edge with no cookies, no legacy backend in the path, and standard caching. Same content Google already sees, delivered correctly.
Hypothesis 2: The XML sitemap is routed the same way, with a larger downstream impact
What we think. sitemap.xml is the primary mechanism by which a 23,000-product catalogue is discovered and refreshed in Google's index. As with robots.txt, the content is correct: the URLs are the right URLs. Our hypothesis is that the plumbing is the same, and that the consequences are more material because of the size and frequency of sitemap fetches.
Why we think it. Every observed sitemap request is forwarded to the legacy backend, which generates a large XML payload on the fly, attaches the same three legacy cookies (frontend_cloud9living, XSRF-TOKEN, catalog_scope), and prevents caching. The downstream effects we would expect, and which are consistent with what we are seeing:
- The sitemap is significantly larger than robots.txt, so each origin generation is more expensive in time and compute.
- Google fetches sitemaps repeatedly to detect new and changed URLs; slow sitemap responses translate directly into slower discovery of new products.
- Where sitemap fetches are slow or intermittently unreliable, Google falls back to crawling URLs it already knows, over-crawling popular pages and under-crawling the long tail. This pattern is visible in our current crawl data.
If validated, the resolution mirrors Hypothesis 1. Move sitemap generation into the Vercel platform and serve it from the edge as a sitemap index, with the legacy backend removed from the path.
Hypothesis 3: Googlebot is being bucketed into the on-site A/B test alongside real users
What we think. An A/B test is currently running across the homepage, category pages, and product pages. Approximately half of visitors are served variant A and half variant B, which is appropriate for a customer-facing experiment. Our hypothesis is that Googlebot is being treated identically to a real shopper, and that the test framework is therefore exposing search engines to randomised variant assignment rather than to a single canonical version of each URL.
Why we think it. When Google fetches the homepage, the response sets an ab-testing cookie, and the request is internally rewritten to a variant-specific path (for example /B/homepage). On the next crawl, Google can land in the opposite variant, encounter materially different HTML at the same URL, and have no signal that the two responses are intended to represent the same page. We would expect three indexing consequences from this pattern, all of which are recognised risks in published SEO and Google guidance:
- Indexing is deferred. When Google sees the same URL return materially different HTML on consecutive crawls, its quality systems tend to hold back on indexing while they reconcile which version is canonical. This is a well-documented driver of "Crawled - currently not indexed" status in Search Console.
- Ranking signals are split. Links, structured data, page-quality signals, and Core Web Vitals are attributed to whichever variant URL Google happened to crawl, rather than to a single canonical product URL. With a 6,055-product catalogue and at least two variants each, Google effectively sees roughly twice the URL surface area we actually maintain.
- The internal test setup is exposed externally. The response header
X-Matched-Path: /B/homepageis visible to anyone reading response headers, including competitors and third-party tooling. This is not a crawl issue in itself, but it is an avoidable disclosure of the experimentation framework.
If validated, the resolution is the one Google publishes in its own A/B testing guidance. Detect known crawlers and serve them the canonical version of the page, without the cookie and without the variant rewrite. The test continues unchanged for real users; Google sees one stable version of every URL.
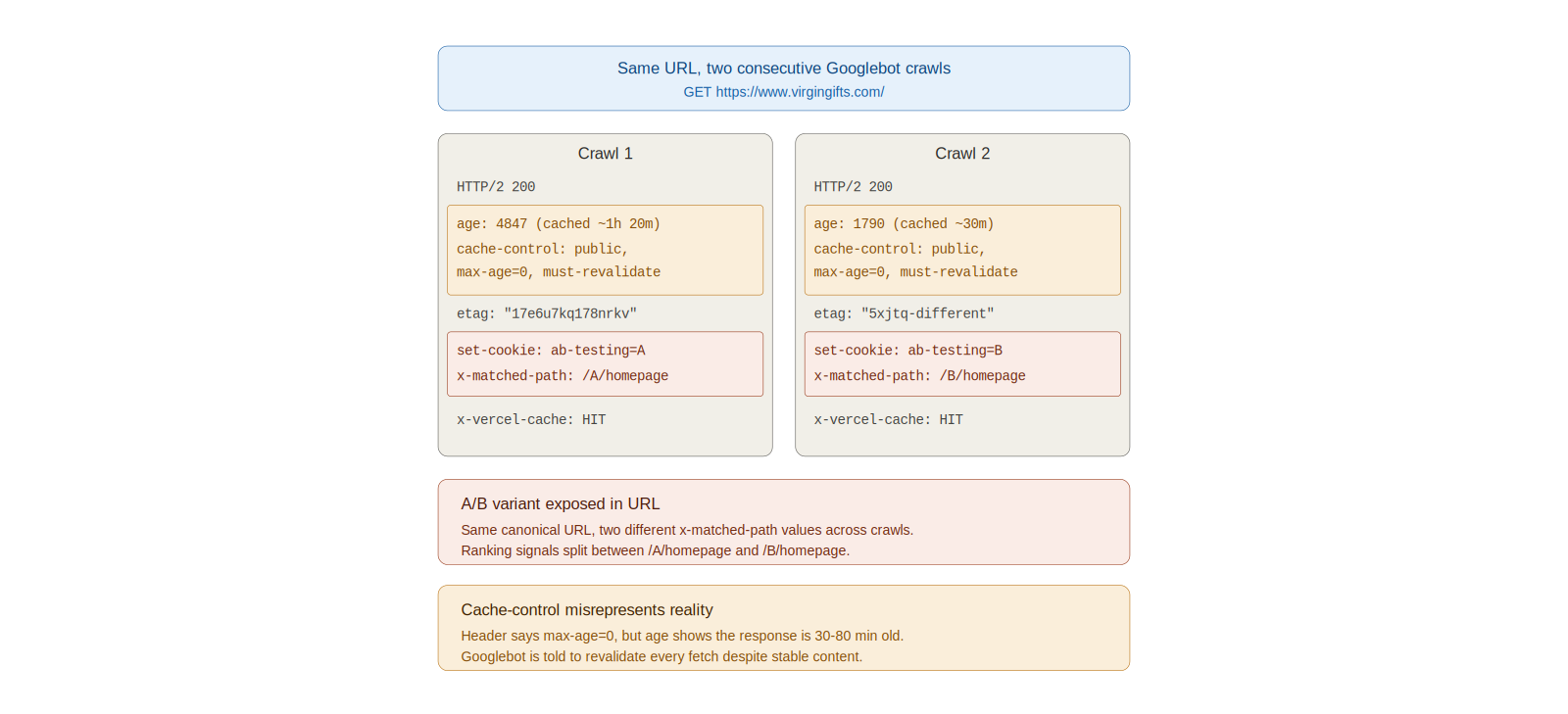
Two consecutive Googlebot crawls of the same canonical URL (https://www.virgingifts.com/) return different x-matched-path values and a different ab-testing cookie value. This is the variant exposure being described, captured directly from response headers.
Hypothesis 4: The legacy virginexperiencegifts.com domain is still serving its own robots.txt and sitemap, and could be redirected as the migration completes
It's normal practice to keep both files reachable on the old domain during the active migration window so Google can verify the move. Now that the root redirect is established and the rebrand is past its initial phase, our suggestion is that the same redirect treatment be extended to /robots.txt and /sitemap.xml (and /sitemap/*), so the canonical brand domain owns these signals end-to-end.
If validated, the resolution is straightforward. Add 301 redirects on virginexperiencegifts.com for /robots.txt, /sitemap.xml, and any sub-sitemap paths, pointing to the equivalent paths on virgingifts.com. This sits alongside, rather than replacing, the work in Hypotheses 1 and 2: those fix where the destination files are served from; this removes the legacy-domain copy from the picture.
What this is costing us right now
This is not theoretical. The Cloudflare bot logs show real impact today:
- Google fetches our robots.txt 212 times every day. Virgin Experience Days (VED), another site within the group that has the file configured correctly, is fetched fewer than 44 times per day - about 5× less. On a per-unit-of-crawl basis, ours is being fetched ~30× more often than VED's, purely because of how the file is configured.
- Google Search Console shows the instability directly. On 11 April, Google fetched our robots.txt 9 times in roughly two hours and 4 of those came back as "Not Fetched – N/A" (failures). VED in the same period: 5 fetches across 4 weeks, zero failures. This is a Google-side record, not our interpretation.
- Every wasted fetch is a fetch not made on a product page that needs indexing. Crawl budget spent re-fetching robots.txt is crawl budget not spent on the catalogue.
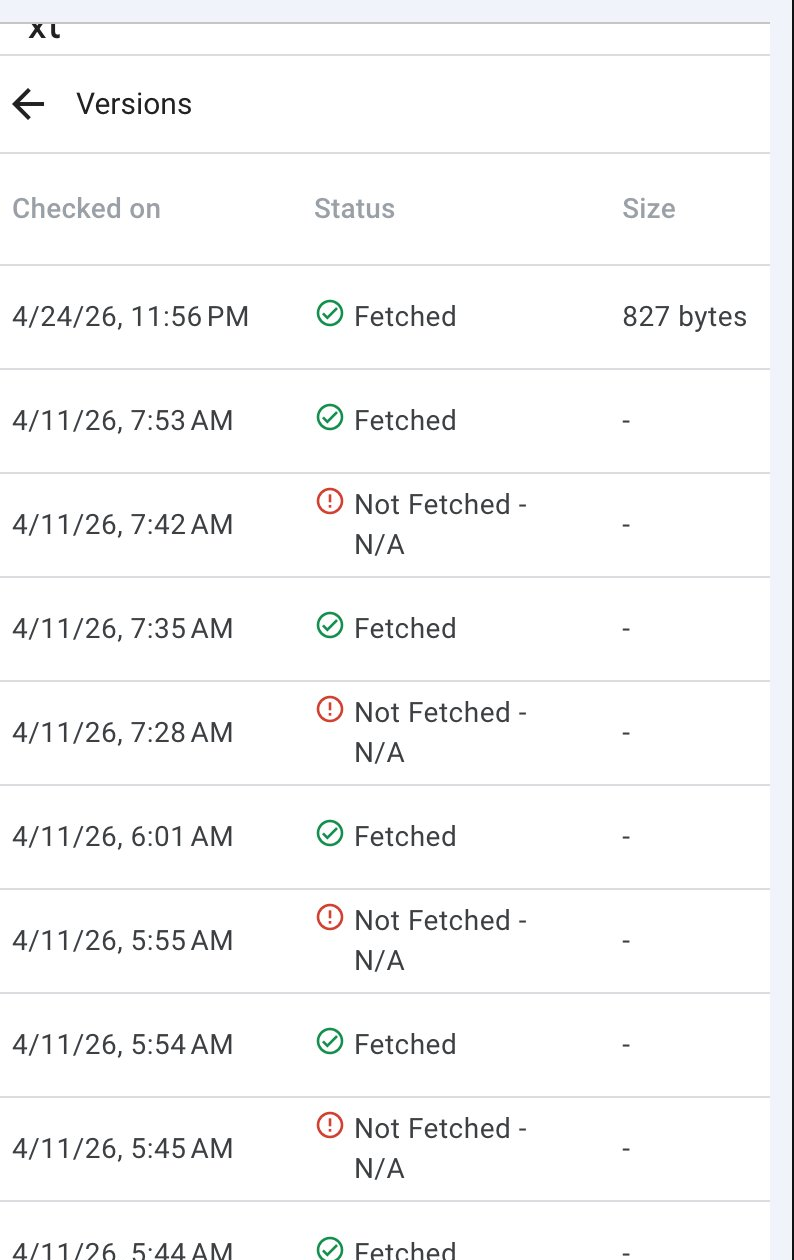
Virgin Gifts (virgingifts.com/robots.txt) - GSC fetch-versions history. Multiple "Not Fetched - N/A" entries on 11 April between 5:45 AM and 7:42 AM, clustered between successful fetches. This is the failure pattern referenced above.
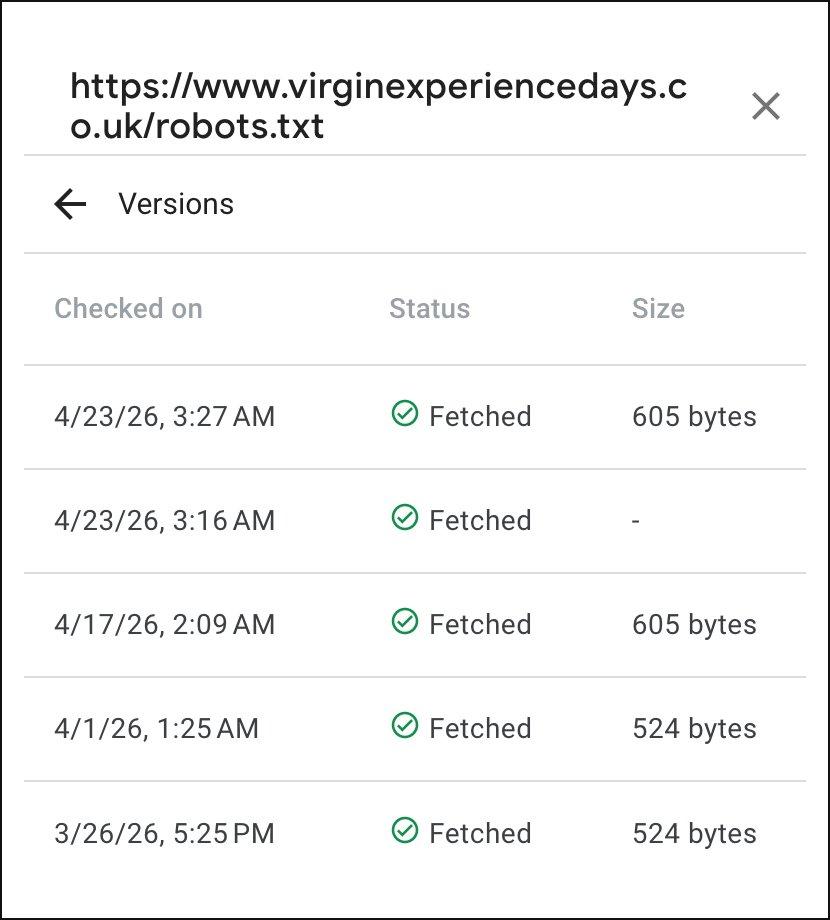
Virgin Experience Days (virginexperiencedays.co.uk/robots.txt) - same GSC view, different property. All "Fetched", spread over weeks, no failures. This is the steady-state pattern we'd expect from a correctly configured robots.txt and is the direct contrast to the VG capture above.
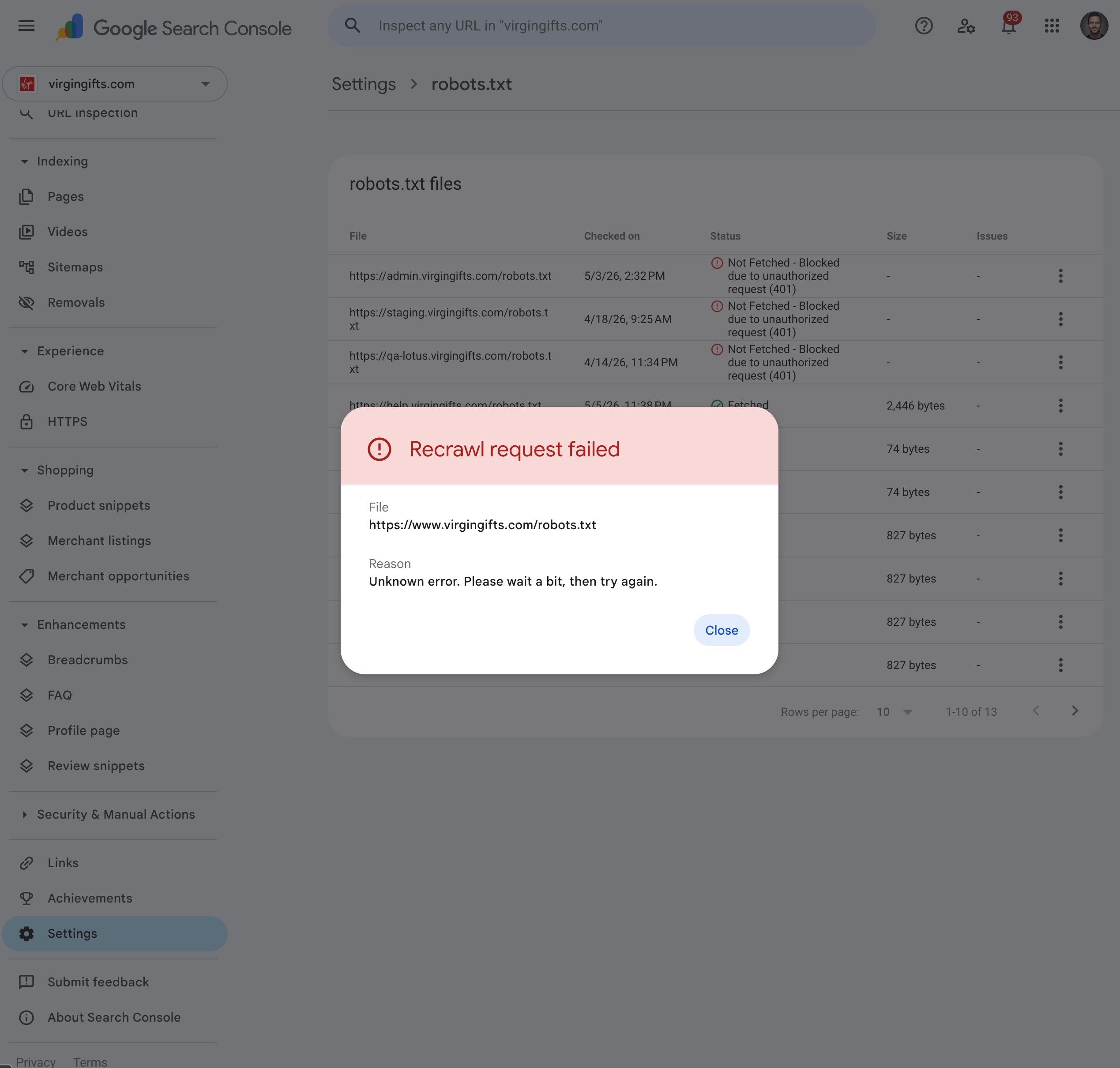
Captured today (6 May 2026). A manual recrawl request submitted from inside GSC for https://www.virgingifts.com/robots.txt returned "Recrawl request failed - Unknown error. Please wait a bit, then try again."
What needs to happen
All three issues are fixable. Subject to validation by the engineering team, the actions we'd propose are:
- Move
robots.txtout of the legacy backend path so it's served by Vercel directly, with the correctContent-Type: text/plainheader, no cookies, nono-storedirective, and standard edge caching. The content stays the same; only the delivery path changes. - Move
sitemap.xmlout of the legacy backend path, served from Vercel as a proper XML file (Content-Type: application/xml) and structured as a sitemap index (multiple chunked sub-sitemaps rather than one large file regenerated per request). Same content, same URLs, delivered in a way Google can actually cache and parse to spec. - Bypass the A/B test for known crawlers, so Googlebot is served a single canonical version of each page rather than being randomly assigned to variant A or B. The test continues unchanged for real users.
- Redirect
/robots.txtand/sitemap.xmlonvirginexperiencegifts.comwith 301s to the equivalent paths onvirgingifts.com, completing the migration cleanup. The root domain redirect is already in place; this extends the same treatment to the SEO utility files. - Review the rate-limit configuration so verified Googlebot requests aren't being caught alongside other automated traffic (this is the most likely cause of the elevated 429 volume on VG vs zero on VED, and is covered in the headline metrics section).
If validated and implemented, the outcomes we'd expect are:
- Google's crawl of the site becomes faster and more reliable, because
robots.txtandsitemap.xmlare no longer dependent on the legacy backend's responsiveness. - Crawl budget is redirected from re-fetching utility files to product and category pages.
- Google sees a single canonical version of every indexable page rather than being assigned to one half of an A/B test on each visit.
- The legacy Cloud9Living infrastructure stops appearing in response headers Google records.
Each of the four actions above is examined in more detail in the technical section, with the supporting evidence and code-level starting points for the team to validate.
Is this just how all retail sites work?
No. We checked the same two files on 14 other retail and gifting sites on 28 April 2026 to make sure this isn't a category convention. The findings are clear:
- No other site in the comparison sets first-party application/session cookies on these public files. Virgin Gifts is alone in attaching three business cookies (
frontend_cloud9living,XSRF-TOKEN,catalog_scope) to every robots.txt and sitemap.xml request. - Two other sites on the exact same hosting platform (Under Armour and Sonos, both on Vercel) get this right - their robots.txt files are cached at the edge and served instantly. The platform is not the problem; our configuration is.
- The cleanest examples in the dataset are Oliver Bonas, Nike, and Parade, all of which serve robots.txt with zero cookies and long-cache headers.
In short: the problem on virgingifts.com is a property of our application stack (the legacy Cloud9Living backend still being in the path), not an industry norm. Full evidence is in the technical section below.
Headline metrics (30 days, both sites)
| Metric | virginexperiencedays.co.uk | virgingifts.com |
|---|---|---|
| Total requests | 46.1M | 28.6M |
| Bot share of traffic | 23% | 36% |
| Unique IPs | 186k | 3.81M |
| Googlebot requests | 2.51M | 0.93M |
| Bingbot requests | 1.80M | 0.38M |
| 200 responses | 83.5% | 82.9% |
| 308 (perm redirect) | 1.66M (3.6%) | 14k (0.05%) |
| 404 responses | 1.89M (4.1%) | 180k (0.63%) |
| 403 forbidden | 1.7k | 529k (1.85%) |
| 429 rate-limited | 0 | 2.57M (9.0%) |
| Status code 0 (aborted) | 3.95M (8.6%) | 0 |
What's structurally different, and why it matters for Google
1. Googlebot is crawling VED ~2.7x as much as VG, despite VG being a smaller site
VED gets 2.51M Googlebot hits/30 days (~84k/day). VG gets 925k (~31k/day). For a site indexing US ecommerce inventory, 31k Googlebot hits/day looks low, and the gap is more likely the result of suppression than a natural baseline. Combined with VG's elevated 429/403 volume, the most plausible explanation is that VG's rate limiter is catching legitimate Googlebot requests alongside other automated traffic. If that is the case, it would have a direct knock-on effect on indexation, freshness, and SERP coverage.
2. VG has 2.57M 429 rate-limit responses in 30 days; VED has zero
This is the single biggest divergence between the two sites. Around 9% of all VG traffic is being throttled at the platform layer. VED records no 429s across 46M requests in the same window. This points to a different traffic-handling strategy rather than a small configuration difference. The consideration here is that Vercel's rate limiter does not whitelist verified Googlebot IPs by default in the way a Cloudflare bot manager configuration typically does, so bursty Googlebot crawls can trigger 429s and back-off behaviour.
3. VG sits on Vercel directly; VED sits behind Cloudflare in front of Vercel
Confirmed in earlier curl checks. Cloudflare's bot management verifies Googlebot via reverse-DNS and exempts it from rate limits. Vercel's edge protection is less Googlebot-aware. This is most likely the architectural root of the crawl gap.
4. Bot composition is radically different
VED top three bots: Googlebot (23%), Bingbot (17%), Generic Bot (12%), well-identified, mostly legitimate.
VG top three bots: Generic Crawler (35%), Generic Bot (25%), Googlebot (9%). Around 60% of VG's bot traffic is unidentified. That's likely a mix of scraping, competitive-intelligence and credential-testing-adjacent traffic that the platform isn't classifying. It is most likely what's prompting the rate limiting in the first place: the platform is responding to genuinely unwanted traffic, but in a way that can also catch Googlebot.
5. VG has 3.81M unique IPs vs VED's 186k
Some of this is the Cloudflare-vs-not-Cloudflare effect (Cloudflare consolidates client IPs at its edge, so VED's IP count is suppressed by design). Even allowing for that, 3.81M unique IPs hitting VG in 30 days is consistent with large-scale distributed scraping activity, which lines up with the 60% unidentified bot share.
6. VG's 403 rate is 528k/30 days vs VED's 1.7k
Something at VG is returning a 403 for around 18k requests/day. This could be WAF rules, geo-blocks (the site is US-facing), or bot fingerprint matching. It would be worth understanding what's in this bucket and whether any legitimate users or crawlers are being caught alongside the intended targets.
Technical discovery (for developers)
Evidence
Headers captured via GSC URL Inspection on 2026-04-27 / 2026-04-28.
Homepage, PLP, PDP (Next.js / Vercel - working as intended apart from A/B)
HTTP/1.1 200 OK
Cache-Control: public, max-age=0, must-revalidate
Content-Type: text/html; charset=utf-8
Server: Vercel
Set-Cookie: ab-testing=B; path=/
Vary: rsc, next-router-state-tree, next-router-prefetch, next-router-segment-prefetch
X-Matched-Path: /B/homepage
X-Nextjs-Prerender: 1
X-Nextjs-Stale-Time: 300
X-Vercel-Cache: HIT
The values shown after X-Matched-Path: are not URLs - they are the Next.js internal route templates that Vercel echoes back in this response header. Google requested a clean public URL; the response leaks the internal routing pattern, including the [variation] segment that names the active A/B test bucket. Concrete examples from the same captures:
| Request URL (what Google asked for) | X-Matched-Path returned (internal route) |
|---|---|
https://www.virgingifts.com/ |
/B/homepage |
https://www.virgingifts.com/birthday-gift-ideas |
/[variation]/category/[attributes]/[...slug] |
https://www.virgingifts.com/product/texas/dallas/stock-car-ride-along-32 |
/[variation]/product/[slug]/[[...sku]] |
The [variation] token in the route templates is the A/B bucket. The homepage example shows it resolved to a literal B because that crawl was assigned variant B. PLP and PDP requests in this capture set returned the unresolved template form, which still discloses that variant routing exists.
PLP capture (same GSC URL Inspection session) - https://www.virgingifts.com/birthday-gift-ideas:
HTTP/1.1 200 OK
Age: 275
Cache-Control: public, max-age=0, must-revalidate
Content-Encoding: br
Content-Type: text/html; charset=utf-8
Date: Wed, 29 Apr 2026 07:34:44 GMT
Etag: W/"lwhknwml8v1l5qd"
Server: Vercel
Set-Cookie: ab-testing=B; path=/
Strict-Transport-Security: max-age=63072000; includeSubDomains; preload
Vary: rsc, next-router-state-tree, next-router-prefetch, next-router-segment-prefetch
X-Matched-Path: /[variation]/category/[attributes]/[...slug]
X-Nextjs-Prerender: 1
X-Nextjs-Stale-Time: 300
X-Powered-By: Next.js
X-Vercel-Cache: HIT
X-Vercel-Id: iad1:iad1:iad1::iad1::zsljk-1777448360262-392909d57f80
Transfer-Encoding: chunked
PDP capture (same session) - https://www.virgingifts.com/product/texas/dallas/stock-car-ride-along-32:
HTTP/1.1 200 OK
Age: 26184
Cache-Control: public, max-age=0, must-revalidate
Content-Encoding: br
Content-Type: text/html; charset=utf-8
Date: Wed, 29 Apr 2026 00:29:57 GMT
Etag: W/"dbdktczefw0n6"
Server: Vercel
Set-Cookie: ab-testing=B; path=/
Strict-Transport-Security: max-age=63072000; includeSubDomains; preload
Vary: rsc, next-router-state-tree, next-router-prefetch, next-router-segment-prefetch
X-Matched-Path: /[variation]/product/[slug]/[[...sku]]
X-Nextjs-Prerender: 1
X-Nextjs-Stale-Time: 300
X-Powered-By: Next.js
X-Vercel-Cache: STALE
X-Vercel-Id: iad1:iad1:iad1::iad1::wc2zd-1777448781925-8c09249daabe
Transfer-Encoding: chunked
Three observations across the HP/PLP/PDP set: (1) Set-Cookie: ab-testing=B fires on every page type, confirming bucketing is site-wide rather than homepage-only; (2) X-Matched-Path exposes the [variation] route segment on PLP and PDP in unresolved template form; (3) the PDP response is X-Vercel-Cache: STALE at Age: 26184 (~7.3 hours) while still advertising Cache-Control: public, max-age=0, must-revalidate - the edge is serving stale HTML to Google despite the must-revalidate directive.
Independent verification - terminal curl -sI re-run on 28 April 2026 (residential AU client → Vercel syd1 edge, both default and Googlebot user agents). Field-by-field comparison against the GSC capture above:
| Header field | GSC URL Inspection | Terminal curl (homepage / PLP) | Match |
|---|---|---|---|
| Status | 200 OK |
200 |
✅ |
cache-control |
public, max-age=0, must-revalidate |
identical | ✅ |
content-type |
text/html; charset=utf-8 |
identical | ✅ |
server |
Vercel |
identical | ✅ |
vary |
rsc, next-router-state-tree, next-router-prefetch, next-router-segment-prefetch |
identical | ✅ |
set-cookie: ab-testing= |
B |
B (homepage) / A (PLP) - value present every request |
✅ |
x-matched-path |
/B/homepage, /[variation]/category/..., /[variation]/product/... |
/B/homepage, /[variation]/category/[attributes]/[...slug] |
✅ |
x-nextjs-prerender |
1 |
1 |
✅ |
x-nextjs-stale-time |
300 |
300 |
✅ |
x-vercel-cache |
HIT |
HIT (age: 2676–3006s) |
✅ |
| Bot UA vs default UA | n/a (always Googlebot in GSC) | byte-identical headers between default and Googlebot UA | ✅ - confirms no UA-based branching at the Vercel layer |
Notable: between two consecutive curls in the same session (homepage and PLP, milliseconds apart), the ab-testing cookie returned different values (B then A). This confirms the variant is assigned per route, not per session - every Googlebot URL request is independently bucketed.
robots.txt and sitemap.xml (legacy PHP origin - issues observed)
HTTP/1.1 200 OK
Cache-Control: no-store, no-cache, must-revalidate
Expires: Thu, 19 Nov 1981 08:52:00 GMT
Server: Vercel
Set-Cookie: frontend_cloud9living=...; Max-Age=10800; HttpOnly
Set-Cookie: XSRF-TOKEN=...; Max-Age=1777350301
Set-Cookie: catalog_scope=...
X-Vercel-Cache: MISS
Independent verification - terminal curl -sI re-run on 28 April 2026 against /robots.txt and /sitemap.xml, both default and Googlebot user agents. Field-by-field comparison against the GSC capture above:
| Header field | GSC URL Inspection | Terminal curl | Match |
|---|---|---|---|
| Status | 200 OK |
200 |
✅ |
cache-control |
no-store, no-cache, must-revalidate |
identical | ✅ |
expires |
Thu, 19 Nov 1981 08:52:00 GMT |
identical | ✅ |
server |
Vercel |
identical | ✅ |
set-cookie: frontend_cloud9living |
present, Max-Age=10800; HttpOnly; secure; domain=.virgingifts.com |
present, identical attributes (fresh session ID per request) | ✅ |
set-cookie: XSRF-TOKEN |
present, far-future Max-Age |
present, Max-Age=1777357051 (~56 years) |
✅ |
set-cookie: catalog_scope |
present | present, value {"closest_region_id":"1","current_region_id":"1","scope_to_region":false} |
✅ |
x-vercel-cache |
MISS |
MISS every request |
✅ |
content-type |
absent | absent (no media type declared) | ✅ - response declares no type while also sending nosniff |
x-content-type-options |
nosniff |
nosniff |
✅ |
x-frame-options |
SAMEORIGIN |
SAMEORIGIN |
✅ |
| Bot UA vs default UA | n/a | byte-identical between default and Googlebot UA | ✅ - confirms no UA-based branching for utility files |
Both robots.txt and sitemap.xml produce identical structural responses: same no-store cache directive, same three Set-Cookie headers, same MISS on the Vercel edge cache. Confirmed twice on 28 April 2026, ~45 minutes apart, all four UA combinations.
Peer comparison - robots.txt and sitemap.xml across 15 retail domains
Captured 28 April 2026 from a single AU client (Brisbane), 15 peers × 2 files × 2 user agents (default + Googlebot-spoofed) = 60 rows.
Condensed view of /robots.txt behaviour, default UA:
| Domain | Platform | Status | Cookies on robots.txt | Edge cache | Notes |
|---|---|---|---|---|---|
| virgingifts.com | Vercel | 200 | 3 first-party app/session (frontend_cloud9living, XSRF-TOKEN, catalog_scope) |
MISS | Only domain in set with first-party application cookies |
| underarmour.com | Vercel | 200 | 0 | HIT (age 688) | Same platform, no cookies, edge cached |
| sonos.com | Vercel | 200 | 0 | HIT | Same platform, stricter no-store directive, still HIT |
| oliverbonas.com | Cloudflare | 200 | 0 | (HIT prior hops) | max-age=31536000 - cleanest example |
| nike.com | - | 200 | 0 | - | max-age=85712 |
| parade.com | - | 200 | 0 | - | max-age=60 |
| everlane.com | Shopify | 200 | 7 (Shopify platform: _shopify_*, localization, cart_currency) |
- | Platform-level, not first-party app state |
| allbirds.com | Shopify | 200 | 7 (Shopify platform) | - | Same Shopify pattern |
| gymshark.com | Shopify | 200 | 7 (Shopify platform) | - | Same Shopify pattern |
| chubbiesshorts.com | Shopify | 200 | 1 (__pack) |
- | max-age=86400 |
| ssense.com | - | 200 | 6 (consent/personalisation: gdprCountry, visitorId, cookieDisclaimerAccepted, …) |
- | Personalisation, not session-bearing in VG sense |
| buyagift.co.uk | Imperva | 200 | 3 (Imperva CDN: nlbi_*, visid_incap_*, incap_ses_*) |
- | Direct UK competitor - cookies are security-layer artefacts, not app state |
| aritzia.com | Cloudflare | 403 | 1 (__cf_bm) |
- | Excluded - bot-mitigation block |
| hims.com | Cloudflare | 403 | 1 (__cf_bm) |
- | Excluded - bot-mitigation block |
| xperiencedays.com | - | 403 | 0 | - | Excluded - blocked across all four captures |
Three deltas this dataset establishes
-
Set-Cookieis the load-bearing variable, notcache-control. Vercel's edge will not serve a cached response when the origin response carriesSet-Cookie(mixing one user's cookies into another's). Under Armour and Sonos prove this directly: same platform as VG, equally or more restrictive cache directives (must-revalidate, evenno-store), but zero cookies →x-vercel-cache: HIT. VG ships three cookies → MISS on every fetch. Tighteningcache-controlwill not fix this; removing the cookies will. -
VG is the only domain in the set emitting first-party application/session cookies on a public utility file. The Shopify peers emit 7 cookies but they are platform defaults, not storefront-specific session state. Buyagift's 3 cookies are Imperva CDN artefacts (
nlbi_*= load balancer,visid_incap_*= visitor ID,incap_ses_*= Imperva session), set by the security layer, not the application. SSENSE's cookies are consent and personalisation. VG's three are first-party PHP session, CSRF, and regional catalog state - a category of one in this comparison. -
The category-convention defence is not supported. Buyagift, the closest like-for-like peer (UK experience-gifting), does not attach application cookies to robots.txt. "This is just how gifting sites work" is contradicted by the nearest direct competitor.
What healthy looks like on Vercel specifically - Under Armour's robots.txt response in full:
HTTP/2 200
server: Vercel
cache-control: public, max-age=0, must-revalidate
x-vercel-cache: HIT
age: 688
No cookies, edge cached, must-revalidate semantic preserved. This is the target state.
Caveats Single point in time, single AU vantage, spoofed Googlebot UA (not reverse-DNS-verified), 3 peers excluded due to 403. The "212 robots.txt fetches/day at origin" figure in the parent audit comes from Cloudflare bot logs, not these captures - the captures explain why origin load is high; the bot logs quantify it.
Sitemap header comparison - VG vs two other Vercel-hosted clients
Re-run on 6 May 2026 against /sitemap.xml for VG and two other client sites we have run the same diagnostic on. Both comparators are hosted on Vercel, so platform capability is held constant - any differences are configuration, not stack. Client identities withheld.
| Header | www.virgingifts.com | Vercel client 1 | Vercel client 2 |
|---|---|---|---|
| Status | 200 direct | 200 direct | 200 direct |
| Content-Type | missing | application/xml |
application/xml |
| Cache-Control | no-store, no-cache, must-revalidate |
public, max-age=0, must-revalidate |
public, max-age=3600, s-maxage=3600 |
| Vercel cache | MISS every hit | HIT (age ~7.7h) | HIT (age ~5d) |
| ETag | absent | present | present |
| Last-Modified | absent | present | absent |
| Set-Cookie | 3 cookies incl. frontend_cloud9living, XSRF-TOKEN, catalog_scope |
none | none |
| Expires | Thu, 19 Nov 1981 08:52:00 GMT (anti-cache) |
absent | absent |
| Vary | absent | absent | RSC, Next-Router-State-Tree, Next-Router-Prefetch |
| Content-Length | absent | 845 | 1765 |
Note on the missing Content-Type header. VG's sitemap response declares no media type at all, while also sending x-content-type-options: nosniff. The two together are contradictory: nosniff instructs clients not to infer the type from content, but with no declared type there is nothing to honour.
Why this matters from a Google perspective:
- Google's sitemap documentation requires sitemaps to be served with an XML media type (
application/xmlortext/xml). A missing Content-Type means the response is non-compliant with the spec Googlebot expects. - Googlebot may still parse the file based on the
.xmlextension and the body, but this is fallback behaviour, not guaranteed. A stricter parse path (or future change) could cause the sitemap to be ignored or flagged as "Couldn't fetch" / "Couldn't parse" in Search Console. - Both peer Vercel clients return
Content-Type: application/xmlcorrectly. This is not a platform constraint - it is a configuration choice on VG's side, consistent with the wider finding that the sitemap is being rendered through the legacy backend rather than served as a static asset from the Vercel edge (evidenced by the PHP session cookies, the 1981Expiresheader, andx-vercel-cache: MISSon every request). - Combined with the absence of
ETagandLast-Modified, Googlebot cannot make conditional requests (If-None-Match/If-Modified-Since), so every sitemap fetch is a full transfer to origin. This compounds the same crawl-budget waste pattern documented for/robots.txtearlier in this audit.
robots.txt header comparison - VG vs the same two Vercel-hosted clients
Same diagnostic as above, run on 6 May 2026 against /robots.txt. Same three sites, same vantage, same caveats. Holding the platform constant (all three on Vercel) isolates configuration as the variable.
| Header | www.virgingifts.com | Vercel client 1 | Vercel client 2 |
|---|---|---|---|
| Status | 200 direct | 200 direct | 200 direct |
| Content-Type | missing | text/plain; charset=utf-8 |
text/plain; charset=utf-8 |
| Cache-Control | no-store, no-cache, must-revalidate |
public, max-age=0, must-revalidate |
public, max-age=0, must-revalidate |
| Vercel cache | MISS every hit | HIT (age ~20.5h) | HIT (age ~9m) |
| ETag | absent | present | present |
| Last-Modified | absent | present | present |
| Set-Cookie | 3 cookies (frontend_cloud9living, XSRF-TOKEN, catalog_scope) |
none | none |
| Expires | Thu, 19 Nov 1981 08:52:00 GMT |
absent | absent |
| Content-Length | absent | 104 | 125 |
The pattern is identical to the sitemap finding. VG is the only site of the three not serving /robots.txt as a static asset from the Vercel edge. The two peers return a properly typed, edge-cached, conditionally fetchable response. VG returns an uncached response with no declared media type and three application/session cookies attached.
Why this matters for /robots.txt specifically:
- Missing
Content-Typeis more consequential here than on the sitemap. Google's robots.txt specification (RFC 9309) requires the file be served astext/plain. Googlebot has historically been forgiving, but the spec is explicit, andnosniffagain disables the only fallback path a strict parser would have. If a future Googlebot behaviour change tightens this check, the consequence is not a slow crawl - it is robots rules being misinterpreted or ignored, with site-wide indexing implications. - The session cookies on
/robots.txtare a category error. A robots.txt response should be stateless. Issuing a PHP session, a CSRF token, and a regional catalog scope cookie to every Googlebot fetch is wasted server work, wasted bytes on every response, and a signal to crawlers that this endpoint is being rendered through application code rather than served as a static file - exactly what the headers above confirm. - No edge cache + no conditional GETs = every Googlebot fetch hits origin in full. This is the mechanism behind the "212 robots.txt fetches/day at origin" figure documented earlier in this audit. Both peer Vercel clients return
x-vercel-cache: HIT, so Googlebot is served from the edge without ever touching origin compute. VG returnsMISSon every request becauseCache-Control: no-store, no-cacheexplicitly forbids the edge from caching the response. - The peer evidence makes the platform-defence untenable. Two unrelated Vercel-hosted sites, in different industries, both serve
/robots.txtcorrectly with no special engineering effort - Vercel's default static file handling does it for free. VG's behaviour is the result of routing the request through the legacy backend, not a Vercel limitation.
Named-brand comparison - VG vs Under Armour and Sonos
The same diagnostic against two publicly named retail brands on Vercel: Under Armour (underarmour.com) and Sonos (sonos.com). Both are large-scale retail operations, both appear in the wider 15-domain peer comparison earlier in this audit, and both can be re-tested directly by curl against the live domains.
/robots.txt
| Header | www.virgingifts.com | www.underarmour.com | www.sonos.com |
|---|---|---|---|
| Status | 200 | 200 | 200 |
| Content-Type | missing | text/plain; charset=utf-8 |
text/plain |
| Cache-Control | no-store, no-cache, must-revalidate |
public, max-age=0, must-revalidate |
max-age=0, no-cache, no-store |
| Edge cache | Vercel MISS every hit |
Vercel HIT (age ~2h) |
Vercel HIT |
| ETag | absent | present | present |
| Last-Modified | absent | present | absent |
| Set-Cookie | 3 first-party app cookies | none | none |
| Expires | Thu, 19 Nov 1981 08:52:00 GMT |
absent | absent |
| Served by | Vercel (legacy proxy passthrough) | Vercel edge (geo-routed: x-matched-path: /robots/us/robots.txt) |
Vercel edge (x-matched-path: /robots.txt) |
Both Under Armour and Sonos ship Cache-Control directives that include no-store or no-cache, yet their responses still return x-vercel-cache: HIT. VG ships the same restrictive directives and returns MISS on every request. The differentiator is the Set-Cookie header: Vercel's edge will not cache responses carrying Set-Cookie, regardless of the Cache-Control value. Tightening cache headers on VG will not change the cache state until the cookies are removed.
/sitemap.xml
| Header | www.virgingifts.com /sitemap.xml |
www.underarmour.com /sitemap_index.xml |
www.sonos.com /sitemap.xml |
|---|---|---|---|
| Status | 200 | 200 | 200 |
| Content-Type | missing | text/xml; charset=UTF-8 |
text/xml |
| Server / origin | Vercel (legacy proxy passthrough) | Cloudflare → Salesforce Commerce Cloud (not Vercel) | AWS S3 via CloudFront (not Vercel) |
| Cache-Control | no-store, no-cache, must-revalidate |
no-cache, no-store, must-revalidate |
absent |
| Edge cache | Vercel MISS every hit |
cf-cache-status: DYNAMIC (uncached) |
Served direct from S3 |
| ETag | absent | absent | present |
| Last-Modified | absent | absent | present (15 Oct 2024) |
| Set-Cookie | 3 first-party app cookies | 8 Demandware/SFCC cookies | 2 Akamai bot-manager cookies |
Anti-cache Expires |
Thu, 19 Nov 1981 08:52:00 GMT (PHP session_cache_limiter fingerprint) |
Thu, 01 Dec 1994 16:00:00 GMT (Demandware fingerprint) |
absent |
For /robots.txt, both Under Armour and Sonos serve the file correctly from Vercel's edge: properly typed as text/plain, edge-cached, no cookies attached. The behaviour expected of a robots.txt response on this platform is demonstrably achievable.
For /sitemap.xml, neither brand is hosted on Vercel.
- Under Armour's sitemap is served through Cloudflare to Salesforce Commerce Cloud (Demandware). The architecture and resulting headers mirror VG's: rendered by an application backend, eight session cookies attached, an anti-cache
Expiresfrom a different decade, uncacheable at the edge. Under Armour's/sitemap.xmlat the root also 301-redirects to/en-us/sitemap.xml, which returns 404; the working entry point is/sitemap_index.xml. - Sonos serves their sitemap directly from S3 via CloudFront as a single 18 MB file. The
Content-TypeandETagare set correctly, but a single multi-megabyte sitemap with no index is itself a pattern that does not scale well and is not advisable for catalogues of this size.
The two anonymised Vercel clients in the previous tables remain the closest like-for-like sitemap comparators, since both serve their sitemaps directly from Vercel's edge.
Comparison with Virgin Experience Days (another site within the group)
VED is the closest possible like-for-like reference: same group ownership, same product category (UK experience gifts), comparable Googlebot crawl footprint. Different stack (CloudFront in front of Vercel for HTML; AWS-hosted backend for utility files; Dynamic Yield for client-side personalisation). Architecture inferred from response headers - not confirmed with VED engineering.
| Aspect | virgingifts.com | virginexperiencedays.co.uk |
|---|---|---|
| Perimeter CDN | None observed (Cloudflare DNS-only, Vercel direct) | CloudFront (via: …cloudfront.net) |
| Homepage matched-path | /A/homepage or /B/homepage (varies per request) |
/ (consistent) |
| Product page matched-path | /[variation]/product/[slug]/[[...sku]] |
/product/[slug] |
| Category page matched-path | /[variation]/category/[attributes]/[...slug] |
/c/[...slug] |
ab-testing cookie on HTML |
=A or =B set every response |
Not observed |
| Personalisation approach | Server-side variant routing | Dynamic Yield (client-side, invisible to Googlebot) |
| robots.txt origin | Vercel (legacy passthrough) | AWS (x-ved-server: WAS4) |
| robots.txt cookies | 3 first-party app/session | 2 (AWSALB, AWSALBCORS - load-balancer stickiness only) |
| robots.txt cacheable in practice | No (x-vercel-cache: MISS every fetch) |
Yes (CloudFront x-cache: Hit, age: 1 on second request) |
| GSC robots.txt fetches (Apr) | 9 fetches in ~2 hours on 11 Apr, 4 failures | 5 fetches across 4 weeks, 0 failures |
| Daily Googlebot robots.txt rate | 212/day | <44/day |
Robots.txt headers
| Header | www.virgingifts.com | www.virginexperiencedays.co.uk |
|---|---|---|
| Status | 200 | 200 |
| Content-Type | missing | text/plain |
| Cache-Control | no-store, no-cache, must-revalidate |
absent |
| ETag | absent | absent |
| Last-Modified | absent | absent |
| Set-Cookie | 3 first-party app cookies (frontend_cloud9living, XSRF-TOKEN, catalog_scope) |
2 AWS load-balancer cookies (AWSALB, AWSALBCORS) |
| Content-Length | absent | 605 |
Sitemap headers
| Header | www.virgingifts.com /sitemap.xml |
www.virginexperiencedays.co.uk /sitemap_index.xml |
|---|---|---|
| Status | 200 | 200 |
| Content-Type | missing | text/xml |
| Cache-Control | no-store, no-cache, must-revalidate |
absent |
| ETag | absent | absent |
| Last-Modified | absent | absent |
| Set-Cookie | 3 first-party app cookies | 2 AWS load-balancer cookies |
| Sitemap structure | Single file | Sitemap index → chunked sub-sitemaps (2,022-byte index file) |
VED declares the correct Content-Type on both files and structures its sitemap as an index pointing to chunked sub-sitemaps, which is the pattern recommended for VG's catalogue at scale. Neither file carries ETag or Last-Modified on either site, so conditional GETs are not available in either case. VED's utility files do still attach cookies, though these are AWS load-balancer stickiness cookies rather than first-party application or session state. None of the choices VED has made are platform-specific; each is achievable on Vercel.
Issue 1 - robots.txt served by legacy Cloud9Living backend
Symptoms in headers
Set-Cookie: frontend_cloud9living=...- PHP session cookie named for the pre-acquisition brand.Set-Cookie: XSRF-TOKEN=...; Max-Age=1777350301- ~56-year CSRF cookie, irrelevant on a public static file.Expires: Thu, 19 Nov 1981 08:52:00 GMT- the classic PHPsession_cache_limiterfingerprint.Cache-Control: no-store, no-cache, must-revalidate+X-Vercel-Cache: MISS- every request bypasses the edge and hits origin.- No
Content-Typeheader - the response declares no media type while simultaneously sendingx-content-type-options: nosniff. RFC 9309 requires robots.txt be served astext/plain. Both peer Vercel-hosted clients returntext/plain; charset=utf-8correctly (see comparison table below).
Diagnosis
/robots.txt never reaches Next.js's filesystem or app/ routes. A beforeFiles catch-all rewrite in next.config.mjs of the form { source: '/:path*', destination: '/proxy' } intercepts every path and forwards it to the legacy AWS-hosted backend before Next.js's filesystem lookup runs. Per Next.js's documented rewrite ordering, beforeFiles runs before public/ files and before app/ routes - so any public/robots.txt or app/robots.ts placed in the codebase today is invisible to the request lifecycle. Every Googlebot fetch therefore:
- Matches the catch-all rewrite at the edge.
- Forwards to the legacy backend via
/proxy. - Boots a PHP request lifecycle on that backend.
- Mints a new session and writes three cookies that no crawler will ever send back.
- Returns
no-store, so no downstream cache (Google's, ISP's, or otherwise) can reuse it.
Independently corroborated by GSC Crawl Stats: average Googlebot response time across 1.48M requests over 90 days is 438ms, well above the 150-250ms range expected for a Vercel/Next.js site with edge caching active. The number is consistent with a meaningful share of requests bypassing the edge cache and hitting origin via the legacy proxy passthrough - exactly the mechanism above.
GSC URL Inspection - direct visual
Side-by-side URL Inspection of /robots.txt on the two properties, captured 29 April 2026:
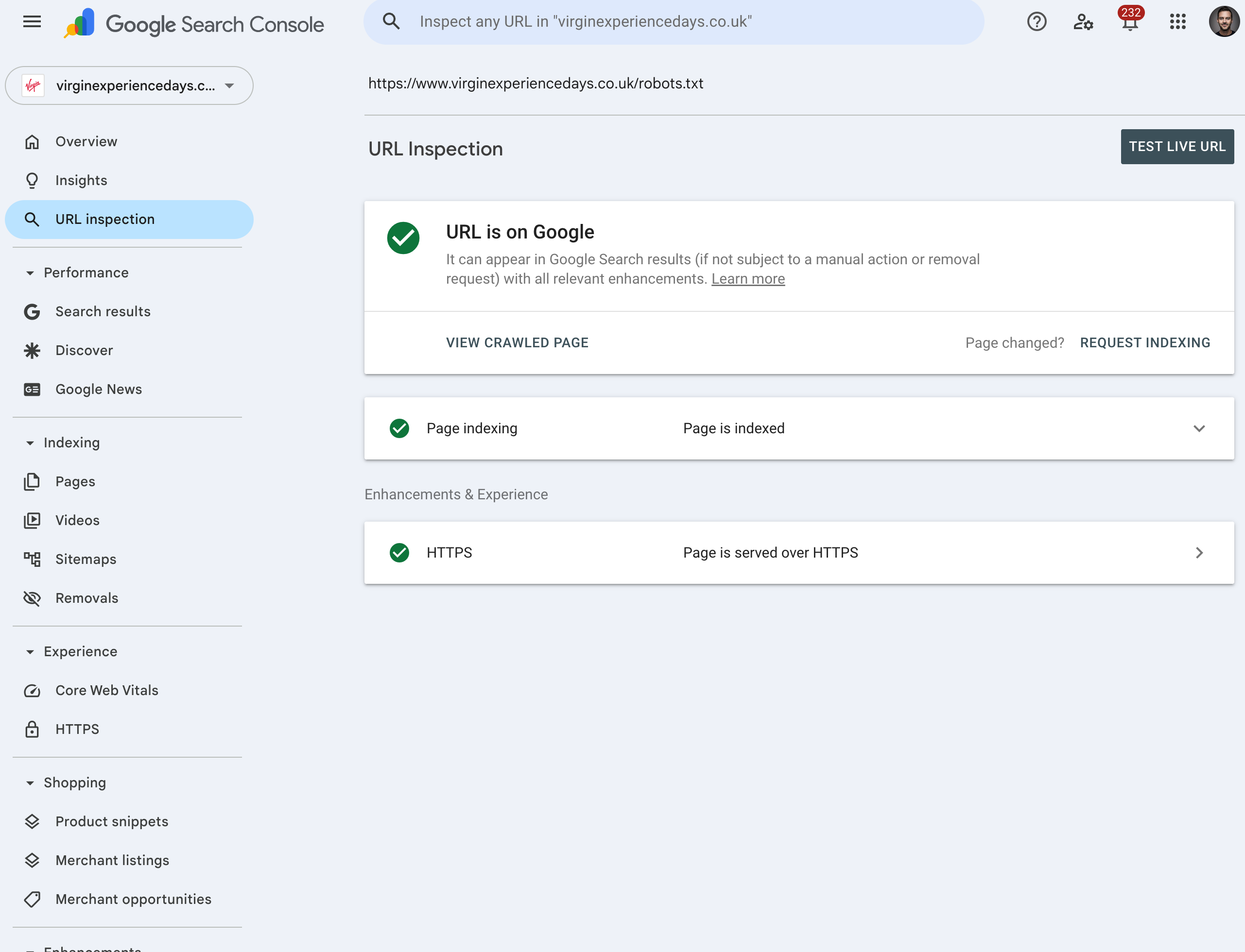
Virgin Experience Days (virginexperiencedays.co.uk/robots.txt) - control. URL is on Google, Page is indexed, served over HTTPS. This is the expected state.
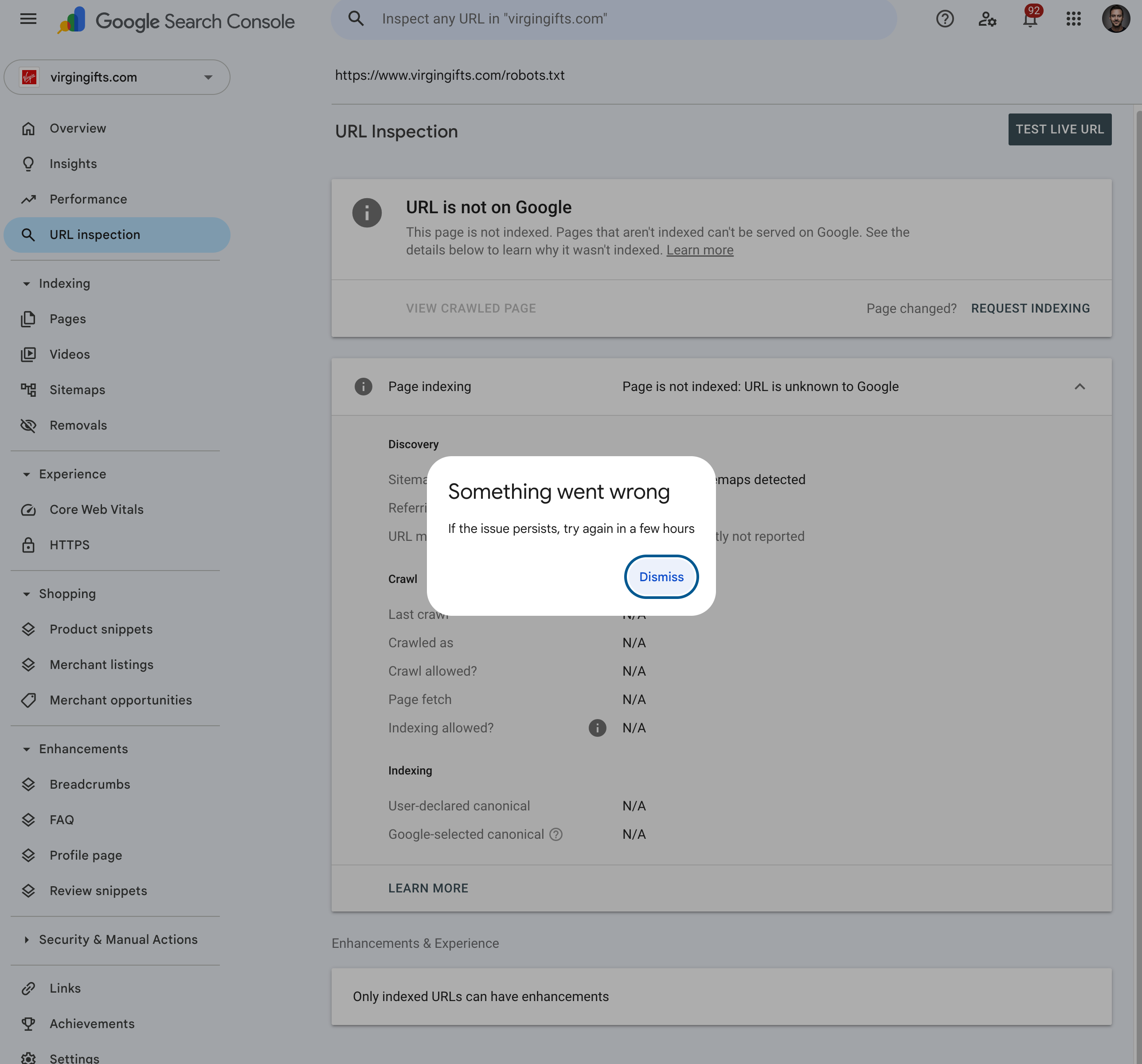
Virgin Gifts (virgingifts.com/robots.txt) - failure mode. URL is not on Google / Page is not indexed: URL is unknown to Google. Every Crawl field reads N/A: Last crawl, Crawled as, Crawl allowed?, Page fetch, Indexing allowed?. GSC's own live-inspection backend errors out with "Something went wrong."
The N/A pattern is diagnostic. It is not "fetched and disallowed" or "fetched and noindex" - those would populate the Crawl fields with concrete values. N/A across the board means Google has never recorded a successful retrieval of this URL. That is the same failure class as the 11 April incident already documented above (4 of 9 fetches returned Not Fetched – N/A in a two-hour window) - now visible at the property level, not just in per-fetch logs. Combined with the 438ms average response time and the no-store + 3-cookie origin response, the picture is consistent: the legacy proxy passthrough is unstable enough under Googlebot load that a non-trivial share of fetches fail outright.
Fix
A note on the suggestions in this section and the ones that follow. The code snippets and implementation patterns shown under each
Fixheading are not prescriptive. They are starting points to open a discussion - illustrative ideas the engineering team can take, leave, or reshape into something better suited to the codebase. The intent is to make the problem and a possible direction concrete enough to respond to, not to recommend specific code for production use. Any final implementation should be designed and reviewed by the engineering team against the constraints they are working within.
This is a two-step change. Step 2 has no effect until Step 1 ships - the rewrite has to be carved out before Next.js can serve anything from app/.
Step 1 - Carve /robots.txt and /sitemap.xml out of the catch-all. Replace the unconditional '/:path*' source with a negative-lookahead pattern that exempts the static SEO paths:
// next.config.mjs
{
source: '/:path((?!robots\\.txt$|sitemap\\.xml$|sitemap/.*).*)',
destination: '/proxy',
}
Apply the carve-out to every branch of the rewrite config (LEGACY, LOTUS, default fallback) - not just the currently active mode - so that flipping FF_PROXY_MODE or any equivalent flag in future doesn't reintroduce the regression.
Step 2 - Add a static Next.js handler. Once Step 1 is live, add:
// app/robots.ts
import type { MetadataRoute } from 'next'
export default function robots(): MetadataRoute.Robots {
return {
rules: [{ userAgent: '*', allow: '/', disallow: ['/api/', '/cart', '/checkout'] }],
sitemap: 'https://www.virgingifts.com/sitemap.xml',
host: 'https://www.virgingifts.com',
}
}
Target headers post-deploy:
Cache-Control: public, max-age=3600(or longer)- No
Set-Cookie X-Vercel-Cache: HITafter warmupContent-Type: text/plain; charset=utf-8(currently absent - see Issue 1 symptoms)
Issue 2 - sitemap.xml served by legacy Cloud9Living backend
Symptoms Identical to Issue 1: frontend_cloud9living, XSRF-TOKEN, catalog_scope cookies; PHP Expires header; no-store; X-Vercel-Cache: MISS; and no Content-Type header (Google's sitemap spec expects application/xml or text/xml; both peer Vercel-hosted clients return application/xml correctly).
Diagnosis Same root cause as Issue 1: the beforeFiles catch-all rewrite in next.config.mjs forwards /sitemap.xml to the legacy backend before Next.js's filesystem or app/ routes are consulted. The same independent 438ms average Googlebot response time from GSC Crawl Stats applies here - origin load is being incurred on every fetch.
Impact is greater than robots.txt because the sitemap is the primary discovery mechanism for the product catalogue. With 23k+ products, the legacy backend is regenerating a large XML payload for every fetch under no-store, with no opportunity for the edge to absorb the load.
Fix
Same two-step ordering as Issue 1. Step 2 has no effect until Step 1 (the beforeFiles carve-out) ships.
The carve-out from Step 1 of Issue 1 already exempts sitemap.xml and sitemap/*, so no additional rewrite change is needed.
Step 2 - Generate as a sitemap index. With a 23k+ URL catalogue, a single-file sitemap is the wrong default. Single-file is well under the 50k hard limit, but a chunked index gives faster regeneration, finer-grained cache invalidation, and lets Google fetch chunks in parallel.
// app/sitemap.ts - the index, listing N chunk URLs
import type { MetadataRoute } from 'next'
export const revalidate = 3600
export default async function sitemap(): Promise<MetadataRoute.Sitemap> {
const totalProducts = await getProductCount()
const chunkCount = Math.ceil(totalProducts / 5000)
return Array.from({ length: chunkCount }, (_, i) => ({
url: `https://www.virgingifts.com/sitemap/${i}.xml`,
lastModified: new Date(),
}))
}
// app/sitemap/[chunk]/route.ts - each chunk
export const revalidate = 3600
export async function GET(
request: Request,
{ params }: { params: { chunk: string } }
) {
const chunk = parseInt(params.chunk, 10)
const urls = await getProductsForChunk(chunk, 5000)
// return XML for these 5,000 URLs
}
5,000 URLs per chunk is a reasonable default. Can be tuned. Set revalidate per chunk to match catalogue change rate.
Issue 3 - A/B test assigning variants to Googlebot
Symptoms
Set-Cookie: ab-testing=B; path=/on every HTML response, including those fetched by Googlebot via GSC.X-Matched-Path: /B/homepage,/[variation]/category/...,/[variation]/product/...- the variation segment is part of the internal route and surfaced in the response header.Vary: rsc, next-router-state-tree, next-router-prefetch, next-router-segment-prefetch- note the absence ofVary: Cookie. The edge cache is not keyed on the A/B cookie, so whichever variant lands in cache first is served to everyone for that route until revalidation.
Diagnosis
A middleware layer somewhere in the request path is assigning every incoming request (including Googlebot) to an A/B bucket, setting the ab-testing cookie, and rewriting to a variant route under /[variation]/.... Two distinct problems:
- SEO - Google should be served a single canonical version. Variant assignment for crawlers can cause inconsistent indexing, especially if A and B differ in content, internal links, or structured data. Google's official guidance is to bypass tests for crawlers or serve them the original.
- Information leak -
X-Matched-Pathexposes the internal rewrite target, including the active variant name, to anyone reading response headers (competitors, agencies, browser devtools).
The middleware location is not yet confirmed. The router app (vg-router) does not perform variant assignment - its rewrites all forward to /proxy or to downstream apps. Likely candidates are:
- The
veg-browseNext.js app whenFF_PROXY_MODE=LOTUS(or equivalent flag), where its own middleware would run after the router has handed the request off. - The legacy backend itself, with the
Set-Cookie: ab-testing=...and the/[variation]/...rewrite happening on the AWS side and surfacing back through the Vercel proxy. - A separate middleware in another repo or package not yet identified.
Confirmation of the assignment point is required before the fix below is applied to the right codebase. The fix shape itself is the same regardless; only the file location changes.
Fix
- In whichever middleware performs the variant assignment, short-circuit for known crawlers using Next.js's built-in helper. Serve the control variant via a named constant (not a hardcoded
/A/) and do not set theab-testingcookie:
```ts import { userAgent, NextResponse } from 'next/server'
const CONTROL_VARIANT = 'A' // single source of truth for the canonical variant
export function middleware(request: NextRequest) {
const { isBot } = userAgent(request)
if (isBot) {
return NextResponse.rewrite(
new URL(/${CONTROL_VARIANT}${request.nextUrl.pathname}, request.url)
)
}
// ...existing variant assignment for real users
}
```
userAgent().isBot is officially documented in Next.js, covers Googlebot, Bingbot, AdsBot, and other major crawlers, and is maintained as crawlers evolve. Routing bots via a CONTROL_VARIANT constant rather than a hardcoded path means the canonical variant can be swapped without touching the bot-bypass code path. (Fallback for environments without next/server's helper: a regex on user-agent matching /googlebot|bingbot|duckduckbot|baiduspider|yandex|applebot/i - structurally weaker but acceptable.)
For higher confidence, pair UA matching with reverse-DNS verification per Google's official Googlebot verification guidance: resolve the requesting IP, confirm the hostname ends in googlebot.com / google.com, then forward-resolve the hostname back. Cache the result per IP for 24h.
- Strip
X-Matched-Pathbefore returning from middleware:
ts
const response = NextResponse.rewrite(...)
response.headers.delete('x-matched-path')
return response
- Confirm canonical tags point to the non-variant URL on every variant page. Per Google's documented A/B testing guidance: use
rel=canonicalto credit link/ranking signals back to the original URL, and 302 (not 301) if redirecting between variants - the test is intended to be temporary and a 301 risks consolidating the variant URL into Google's index permanently.
On caching strategy - the existing path-rewrite pattern (/A/..., /B/... as separate cache entries on the Vercel edge) is the correct model. This is what Vercel's own A/B testing example uses and it works without any Vary header - the edge naturally caches each variant under its rewritten path. Adding Vary: Cookie would key the cache by every user's unique cookie value and destroy hit rate. The bug is bots being assigned to the test, not how the cache is keyed.
Issue 4 - Redirect management
Two legacy domains feed traffic into virgingifts.com: the Cloud9Living estate and virginexperiencegifts.com. Both carry historical URL paths that need to be redirected to the canonical Virgin Gifts equivalents, and the volume will grow as the migration completes. We have not directly observed how those redirects are currently implemented; the recommendation below applies regardless.
Diagnosis
Redirects of this shape - bulk, static, domain-wide, not dependent on application state - sit awkwardly when handled in Vercel middleware. Each request has to enter the application layer to be redirected; the rule set has to be updated and redeployed through application code; and the redirect surface tends to split across whichever middleware files happen to own pieces of it. The further the rules drift from a single auditable source, the harder migration close-out becomes.
Fix
Consolidate bulk and domain-wide redirects at the Cloudflare layer rather than in Vercel middleware. Cloudflare provides two purpose-built mechanisms that, between them, cover the majority of migration redirect work:
- Bulk Redirects - upload a list of source → destination URL pairs. Suited to large, static rule sets such as legacy Cloud9Living paths to their VG equivalents.
- Single Redirects - rule-based with pattern matching, regex, and host/path filters. Suited to wildcard and structural rules such as
virginexperiencegifts.com/*→virgingifts.com/$1.
Operating redirects at this layer gives us:
- A single management surface for both legacy domains, rather than redirect logic split across middleware files.
- Auditable, bulk-editable rule sets owned by infrastructure rather than application code, removing the deploy cycle from redirect changes.
- Static redirect handling moved out of the application path, which is the preferred pattern when the rules do not depend on application state.
- Consistency with how we have configured other Cloudflare-fronted clients during past migration work.
This recommendation should be validated by engineering and infrastructure against any operational reasons specific routes need to remain in middleware - for example, rules that genuinely depend on session, auth, or request-time application state. Anything genuinely state-dependent should stay where it is; anything static should move.
Recommended actions
Issues 5-8 are diagnosed in the section that follows.
- Issue 1 - in whichever middleware hosts the variant assignment, bypass A/B bucketing for known crawlers and serve the canonical variant. Use Next.js's built-in
userAgent().isBothelper fromnext/server: officially documented, covers Googlebot, Bingbot, AdsBot, and other major crawlers. WhenisBotreturns true, rewrite to aCONTROL_VARIANTconstant (e.g.A) rather than hardcoding/A/so the canonical variant can be swapped without touching the bypass code. Do not set theab-testingcookie on bot responses. StripX-Matched-Pathfrom the outbound response withresponse.headers.delete('x-matched-path')before returning. The full snippet is in the Issue 3 fix section above. - Issue 2 - in
next.config.mjs, carve/robots.txt,/sitemap.xml, and/sitemap/*out of thebeforeFilescatch-all, in every config branch. Addapp/robots.ts. - Issue 3 - add the sitemap-index handlers (
app/sitemap.ts+app/sitemap/[chunk]/route.ts). - Issue 4 - move bulk and domain-wide redirects (Cloud9Living and
virginexperiencegifts.comlegacy paths) from Vercel middleware to Cloudflare Bulk Redirects and Single Redirects. Keep only state-dependent redirects in middleware. - Issue 5 - remove the stale
<link rel="index" href=".../sitemap.xml.gz">from legacy templates, OR have the Lotus layer serve/sitemap.xml.gzas a gzipped form of the chunked sitemap. - Issue 6 - either turn
/all-regionsinto a 200 landing page or remove it from internal links andCLOUD_CONFIG. Stop sending crawlers and link equity to a path disallowed inrobots.txt. - Issue 7 - audit the 17,427 category URLs for unique location-relevant content vs near-duplicates. For non-unique permutations, consolidate to a single canonical and 301 the variants, or
noindexand remove from sitemap. - Issue 8 - add
x-robots-tagandlinktoRESPONSE_HEADERS_ALLOW_LISTinveg-legacy-proxy. While in the file, audit forcontent-language,referrer-policy, andstrict-transport-security.
Measuring success
Each fix produces a measurable signal in a system the client already has access to. We will not need to take anything on faith.
| Signal | Where to check | Expected change | Timeline |
|---|---|---|---|
| robots.txt fetch rate | Cloudflare bot analytics / server logs | Drops from 212/day to <5/day | Within 1 week of robots.txt fix |
| GSC robots.txt fetch history | Search Console → Settings → robots.txt | Failure rate drops to zero; fetch cadence stabilises | Within 1–2 weeks |
| A/B matched-path in GSC | Search Console → URL Inspection on sample URLs | Crawled URL shown as canonical, not /A/… or /B/… |
Within 1 week of bot bypass |
| Sitemap fetch latency | Vercel logs / Cloudflare analytics | x-vercel-cache: HIT on warm fetches; origin load drops |
Within 1 week of sitemap fix |
Crawled - currently not indexed |
Search Console → Pages report | Begins declining from current baseline | 4–8 weeks |
| Indexed page count | Search Console → Pages report | Begins increasing | 4–12 weeks |
Important caveat - these fixes remove technical barriers to indexing. They do not address content-level issues (location-variant content overlap, image rendering on category pages) documented separately. Sustained ranking improvement requires the content investment work in addition to this technical work.
Verification checklist (post-deploy)
After the robots.txt, sitemap, and routing fixes (Issues 2, 5, 6):
curl -sI https://www.virgingifts.com/robots.txt
curl -sI https://www.virgingifts.com/sitemap.xml
curl -sI https://www.virgingifts.com/sitemap/0.xml
Pass criteria:
- No
Set-Cookieon any of the three responses. - No
frontend_cloud9living,XSRF-TOKEN, orcatalog_scopeanywhere. Cache-Control: public, max-age>=3600.X-Vercel-Cache: HITafter a warmup fetch (first hit may be MISS).Content-Type: text/plain; charset=utf-8on/robots.txtandContent-Type: application/xmlon/sitemap.xmland/sitemap/0.xml(currently absent).ETagandLast-Modifiedheaders present on all three (currently absent), so Googlebot can issue conditional GETs.- Confirms
app/robots.tsis the actual handler rather than the legacy proxy.
After the proxy header allowlist fix (Issue 8):
Set a test x-robots-tag: noindex and link: <https://example.com/>; rel="canonical" on any legacy-served response, then:
curl -sI https://www.virgingifts.com/<test-path>
Pass criteria: both headers present in the response.
After the A/B bot bypass fix (Issue 1):
curl -sI -A "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)" https://www.virgingifts.com/
curl -sI -A "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)" https://www.virgingifts.com/birthday-gift-ideas
curl -sI -A "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)" https://www.virgingifts.com/product/texas/dallas/stock-car-ride-along-32
Pass criteria:
- No
Set-Cookie: ab-testingon any response. - No
X-Matched-Pathheader. X-Nextjs-Prerender: 1(still served from the prerender layer).- Body content matches the canonical (control) variant across repeated fetches - not random across A and B.
Then verify in GSC URL Inspection on one homepage, one PLP, and one PDP URL: the crawled URL is shown as canonical with no /A/ or /B/ segment.
Architecture and additional findings
Tracing the legacy proxy path through Vercel source (read-only access) and exporting the Cloudflare DNS zone produced four additional findings and confirmed the underlying architecture.
Architecture
- Vercel / Next.js layer (internal codename "Lotus", confirmed by
qa-lotus.virgingifts.comDNS comment and theX-Lotus-Proxy-Tokenheader in source) handleswww.virgingifts.com,staging.virgingifts.com, andqa-lotus.virgingifts.com. - Legacy backend runs on AWS ELBs in
us-east-1and is reached viaproxy-prod.virgingifts.com(CNAME toveg-production-4153048.us-east-1.elb.amazonaws.com). This is the upstream that handles/core/*, account, checkout, admin, API, partners, and serves/robots.txtand/sitemap.xml. - The proxy is implemented in the
app-ved-web-frontendmonorepo atpackages/apps/vg-router/app/proxy/route.ts, delegating to the@virginexperiencedays/veg-legacy-proxylibrary. The Vercel/proxyedge function authenticates to the legacy backend via a sharedX-Lotus-Proxy-Tokenheader, then forwards an allowlisted set of request and response headers. - VG and VED share both the codebase (same monorepo, owned by the UK org) and the AWS account.
This confirms the original finding that legacy Cloud9Living infrastructure is still in the path. It also clarifies which legacy infrastructure: a US East AWS environment proxied through a small Vercel-hosted edge function, not a direct rewrite at the CDN.
Issue 5 - /sitemap.xml.gz referenced by legacy backend but returns 404
Symptoms Pages served by the legacy origin (e.g. /core/user/create) emit a <link rel="index" href="https://www.virgingifts.com/sitemap.xml.gz"> tag in the document head. Direct fetch of that URL:
HTTP/2 404
cache-control: no-store, no-cache, must-revalidate
server: Vercel
Diagnosis The legacy backend templates still reference a gzipped sitemap that the Lotus layer does not serve. A cross-stack mismatch between what legacy HTML advertises and what Lotus routes resolve. Crawlers following the <link rel="index"> hint hit a 404; Search Console may log this as a sitemap reference error depending on how it surfaces the rel.
Fix Either:
- Remove the <link rel="index" href=".../sitemap.xml.gz"> from the legacy templates that emit it, or
- Have the Lotus layer serve /sitemap.xml.gz (it can be a gzipped version of the existing /sitemap.xml produced at the same revalidation cadence).
The first option is simpler and removes the stale reference at source rather than working around it. Severity: HIGH - stale external reference, quick to resolve.
Issue 6 - /all-regions 301-redirects to a disallowed URL
Symptoms
$ curl -sI https://www.virgingifts.com/all-regions
HTTP/2 301
location: /search
/search is explicitly disallowed in robots.txt:
Disallow: /search
Diagnosis The /all-regions URL is referenced as the canonical URL for region ID 1 ("All Locations") in the inline JavaScript catalogue config served on every page. It also corresponds to a navigation concept users would expect to land on. The 301 sends crawlers and link equity to a path Google is told not to crawl. The result is a dead end: the source URL produces a redirect, and the redirect target is excluded from the index, so any inbound links to /all-regions accrue no benefit and any internal navigation pointing there is wasted crawl budget.
Fix Pick one:
- Make /all-regions a 200-response landing page with its own content (preferred if "all locations" is a meaningful user journey), or
- Remove /all-regions from internal links and from the CLOUD_CONFIG regions data so it stops being a discoverable URL.
Severity: MEDIUM - affects a single high-level URL but one that is referenced in every page's inline config, so the discoverability surface is large.
Issue 7 - Sitemap composition is skewed toward category permutations
Note: This finding is already being discussed internally and has been raised previously. It is included here for completeness of the technical picture, not as a new item for action.
Observed counts (28 April 2026)
| Sitemap | URL count |
|---|---|
sitemap-products.xml |
6,234 |
sitemap-categories.xml |
17,427 |
sitemap-pages.xml |
30 |
| Blog (Yoast, three sub-sitemaps) | (separate) |
Diagnosis The category sitemap is 2.8× larger than the product sitemap, which is unusual. The pre-existing inline CLOUD_CONFIG data shows ~140 regions and ~30 top-level categories; the product of those plus subcategories accounts for the high count. This is consistent with heavy regional × category permutation pages - the same category sliced by every region - which is exactly the pattern flagged in the related "VG Global Product URL & Content Analysis" report (Feb 2026: 86% content overlap across location variants).
This is not a defect of the sitemap generator; the sitemap is correctly listing what is indexable. The finding is that the indexable surface itself is dominated by location-variant category pages with low content uniqueness. Submitting them in the sitemap accelerates Google's discovery of duplicate-thin content, which contributes to the "Crawled - currently not indexed" volume documented in the parent audit (16,155 URLs).
Fix This is a content/IA decision rather than a header-level fix:
- Audit how many of the 17,427 category URLs have unique location-relevant content vs near-duplicates of the same product set with a region label, and
- For non-unique permutations, either consolidate to a single canonical and 301 the variants, or noindex them and remove from sitemap.
Severity: MEDIUM - overlaps with prior content-overlap finding; sitemap is a symptom, not the cause.
Issue 8 - Proxy strips X-Robots-Tag and Link response headers from upstream
Source evidence From packages/libs/veg-legacy-proxy/src/const.ts in the live deployment:
export const RESPONSE_HEADERS_ALLOW_LIST = [
'content-type', 'content-length', 'content-disposition', 'content-encoding',
'cache-control', 'expires', 'etag', 'last-modified',
'location', 'set-cookie', 'vary',
'access-control-allow-origin', 'access-control-allow-credentials',
'access-control-allow-headers', 'access-control-allow-methods',
'x-frame-options', 'x-content-type-options',
] as const
The proxy implementation in headers.ts filters upstream response headers to this allowlist; anything not on the list is silently dropped before the response reaches the client.
Diagnosis Two SEO-significant headers are absent from the allowlist:
X-Robots-Tag- used to send indexing directives (noindex,nofollow,noarchive,none) at the HTTP layer, often applied by backend rules to login/account/checkout/filtered-listing pages. If the legacy backend ever sets this header, Googlebot does not see it. This is a silent failure: pages intended to be excluded from index will be fully indexable.Link- used to sendrel="canonical",rel="alternate" hreflang=..., and other relations at the HTTP layer. If the legacy backend uses header-based hreflang or canonicals (some configurations do), those signals are lost.
Verification needed This is a latent issue: whether it is currently affecting indexing depends on whether the legacy backend actually sets these headers. To confirm impact, compare headers from the upstream directly versus through the proxy on a representative set of URLs (a PDP, a faceted PLP, a login page, a checkout step). Any X-Robots-Tag or Link returned by upstream that is missing from the proxied response is direct evidence of signal loss.
Fix One-line change to RESPONSE_HEADERS_ALLOW_LIST:
export const RESPONSE_HEADERS_ALLOW_LIST = [
// …existing entries…
'x-robots-tag',
'link',
] as const
Low risk, immediate effect. Severity: MEDIUM until verified, HIGH if upstream is found to set X-Robots-Tag on pages that should not be indexed.
Diagnostic consistency check
Findings 2 and 3 (dynamic robots.txt and sitemap.xml) reproduce identically across multiple capture windows: cache-control: no-store, no-cache, must-revalidate, x-vercel-cache: MISS on every request, expires: Thu, 19 Nov 1981 08:52:00 GMT, no Content-Type header, no ETag, no Last-Modified. The behaviour is stable, not transient.
For homepage, robots.txt, and sitemap.xml, response bodies are byte-identical between default UA and Googlebot UA. This means bot/human content divergence (if any) is not happening at the Vercel/Lotus layer for these specific URLs. The A/B test exposure documented in Issue 3 is path-level (/A/... vs /B/... in X-Matched-Path), not content-level on these utility files. Any divergence elsewhere - for example on /core/* paths served by the legacy backend - is upstream behaviour and outside the Vercel layer's control.
Remediation summary
| # | Finding | Severity | Effort | Where |
|---|---|---|---|---|
| 1 | A/B variants exposed to Googlebot | HIGH | Medium | Lotus middleware |
| 2 | robots.txt dynamic / uncacheable |
HIGH | Low | Lotus route |
| 3 | sitemap.xml dynamic / uncacheable |
HIGH | Low–Med | Lotus route |
| 4 | /sitemap.xml.gz referenced but 404 |
HIGH | Low | Legacy templates |
| 5 | /all-regions 301 → disallowed /search |
MED | Low | Lotus routing |
| 6 | Sitemap weighted to category permutations | MED | High (content) | Content/IA review |
| 7 | Proxy strips X-Robots-Tag and Link headers |
MED–HIGH | Trivial (1 line) | veg-legacy-proxy lib |
Findings 4 and 7 are the two cheapest wins. All seven are listed in the Recommended actions above.
Evidence sources
- Direct HTTP diagnostics - terminal
curl -sIandcurl -sILagainst the live www.virgingifts.com production environment, run from a residential connection in Brisbane (AU), resolving to Vercel's syd1 region. Five URL types captured (homepage, PDP, PLP, robots.txt, sitemap.xml, plus a static asset and the /blog redirect), each requested twice - once with the default user agent, once with a Googlebot user-agent string - on 27 April 2026 and re-verified 28 April 2026. - Google Search Console URL Inspection - live-fetched response headers for the same URL types, captured from inside GSC on 27-28 April 2026. Used to corroborate what Googlebot itself receives versus the spoofed-UA terminal captures.
- Google Search Console robots.txt fetch history - GSC's index-side record of every robots.txt fetch attempt (Settings → robots.txt). Provides the failure-rate evidence (9 fetches in 2 hours on 11 April, 4 marked "Not Fetched – N/A") and the version-history comparison against VED.
- Cloudflare bot analytics - 7-day Googlebot crawl export, top 100 paths by request count. Source of the 212 robots.txt fetches/day figure, the spiky product-page distribution, and the template-asset crawl share.
- Peer comparator captures - terminal
curl -sILagainst 15 retail and gifting domains (Nike, Under Armour, SSENSE, Parade, Everlane, Aritzia, Hims, Allbirds, Gymshark, Oliver Bonas, Chubbies, Sonos, Buyagift, Xperience Days, plus VG itself), 2 files × 2 user agents = 60 captures. Run from the same AU client on 28 April 2026. - Within-group comparison - the same direct HTTP diagnostics run against virginexperiencedays.co.uk on 27 April 2026 for matched-path / cookie / cache-state comparison.
- Vercel project dashboard - skew-protection configuration screenshot, 27 April 2026. Read-only access to the
vg-routerproject source tree on 28 April 2026 used to inspect the legacy proxy implementation inpackages/apps/vg-router/app/proxy/route.tsand the@virginexperiencedays/veg-legacy-proxylibrary (url.ts,index.ts,headers.ts,security.ts,const.ts). - Cloudflare DNS dashboard - DNS record screenshot, 27 April 2026, used to confirm the perimeter topology (Cloudflare DNS-only, Vercel direct, no CDN absorption layer in front of origin). Full zone export pulled 28 April 2026 to identify the legacy upstream (
proxy-prod.virgingifts.com→ AWS ELB inus-east-1).